Zynq Ethernet Performance
Table of Contents
XAPP1082 Benchmarking Results
This section includes Zynq Ethernet Performance associated with XAPP1082 releases.
XAPP1082 v3.0
XAPP1082 v4.0
Understanding Ethernet Performance
The raw line rate of Ethernet is 1.25Gbps. This is commonly referred to as Gigabit Ethernet after accounting for encoding overheads. The performance of various Ethernet applications is at different layers is lesser than the throughput seen at the software driver or at the Ethernet interface. This is due to the
additional headers and trailers inserted in packet by each layer of the networking stack. Ethernet is only a medium to carry traffic; various protocols like TCP or UDP implement their own header formats.
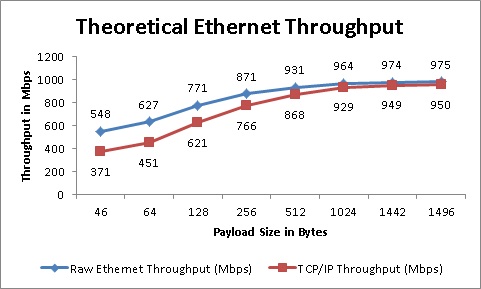
To estimate theoretical Ethernet performance, following is considered-
Based on this we have,
Plotting this for a few payload size values as shown below, we notice
Note: This estimate doesn't account for software stack latencies.
additional headers and trailers inserted in packet by each layer of the networking stack. Ethernet is only a medium to carry traffic; various protocols like TCP or UDP implement their own header formats.
To estimate theoretical Ethernet performance, following is considered-
- Ethernet Overhead : 14B Ethernet Header + 4B Ethernet Trailer (FCS)
- 8B of preamble with 12B of Inter Frame Gap on wire
- 20B TCP Header + 20B IP Header
Based on this we have,
| Raw Ethernet Throughput = | Payload * 1000 |
| (Payload + 18 + 20) |
| TCP/IP Frame Throughput = | Payload * 1000 |
| (Payload + 18 + 20 + 40) |
Plotting this for a few payload size values as shown below, we notice
- Protocol overheads prevent the network cards from reaching wire speed
- Throughput improves with payload size; with increasing payload, impact of a fixed size header/trailer reduces
Note: This estimate doesn't account for software stack latencies.
Ethernet Benchmarking
This section describes Ethernet benchmarking results obtained with netperf.
Netperf provides a network benchmarking tool which can measure throughput and also report CPU utilization.
To use netperf on Zynq Linux, the netperf source can be downloaded and built for ARM Linux using cross-compiler tool chain.
Following netperf commands are useful for benchmarking-
For Zynq as server- (refer XAPP1082 for note on CPU affinity)
For peer PC as client-
The options '-c' and '-C' report CPU utilization for self and remote CPUs.
The first command generates traffic from peer PC towards Zynq - essentially measuring Zynq receive performance.
This runs the TCP_STREAM test by default.
The second command running TCP_MAERTS test measures Zynq transmit performance.
The third command provides option for message size variation with '-D' option.
It should be noted that message size in netperf refers to size of TCP payload in Ethernet packet - the total size of packet on wire will include additional overheads associated with various layers. Please note that results provided (in v1.0 of XAPP1082) are run without -D option where Linux coalesces multiple smaller messages into larger TCP segment thereby showing improved performance at smaller message size values; if actual payload size variation is required for TCP tests, netserver and netperf should be run with an additional '-D' switch along with message size variation (this is updated in v2.0 of XAPP1082).
Use of '-D' switch disables Nagle's algorithm; however TCP being a byte stream service some additional options like changing socket size using -s option may be required to ensure smaller size frames on wire.
Benchmarking is done under near ideal conditions where no other applications are run to interfere with results.
It is noticed that,
This section describes Ethernet benchmarking results obtained with netperf.
Using Netperf
Netperf provides a network benchmarking tool which can measure throughput and also report CPU utilization.
To use netperf on Zynq Linux, the netperf source can be downloaded and built for ARM Linux using cross-compiler tool chain.
Following netperf commands are useful for benchmarking-
For Zynq as server- (refer XAPP1082 for note on CPU affinity)
bash> taskset 2 ./netserver
For peer PC as client-
The options '-c' and '-C' report CPU utilization for self and remote CPUs.
bash> netperf -H <Zynq_IP_address> -c -C bash> netperf -H <Zynq_IP_address> -c -C -t TCP_MAERTS bash> netperf -H <IP address> -c -C -- -m <64|128|256|512|1024> -D
The first command generates traffic from peer PC towards Zynq - essentially measuring Zynq receive performance.
This runs the TCP_STREAM test by default.
The second command running TCP_MAERTS test measures Zynq transmit performance.
The third command provides option for message size variation with '-D' option.
It should be noted that message size in netperf refers to size of TCP payload in Ethernet packet - the total size of packet on wire will include additional overheads associated with various layers. Please note that results provided (in v1.0 of XAPP1082) are run without -D option where Linux coalesces multiple smaller messages into larger TCP segment thereby showing improved performance at smaller message size values; if actual payload size variation is required for TCP tests, netserver and netperf should be run with an additional '-D' switch along with message size variation (this is updated in v2.0 of XAPP1082).
Use of '-D' switch disables Nagle's algorithm; however TCP being a byte stream service some additional options like changing socket size using -s option may be required to ensure smaller size frames on wire.
Benchmarking is done under near ideal conditions where no other applications are run to interfere with results.
Impact of Checksum Offload
Checksum is used to maintain data integrity in TCP/UDP protocols. Normally, this checksum calculation is handled by protocol stack which consumes significant processor bandwidth. This operation tends to be slower when operating larger size Ethernet frames at high line rate. Checksum offloading moves this checksum calculation in outbound (transmit) direction and checksum verification for inbound (receive) direction to hardware. This frees up processor for use in other functions.It is noticed that,
- Checksum Offload improves throughput
- Checksum Offload improves CPU utilization
© Copyright 2019 - 2022 Xilinx Inc. Privacy Policy